Soumyabrata Chaudhuri (Soumya)I’m currently a MS in Computer Science student at UT Austin. Before that, I completed my B.Tech (Honors) degree in Computer Science and Engineering at Indian Institute of Technology (IIT), Bhubaneswar. During my undergraduate studies, I conducted research across interrelated domains, including Machine Learning, Computer Vision, Natural Language Processing, and Multi-Modal Learning. For my B.Tech thesis, I collaborated with Microsoft India to improve the travel-planning process using large language models, under the supervision of Dr. Shreya Ghosh, Dr. Abhik Jana, and Dr. Manish Gupta. I spent a wonderful summer interning at the University of Alberta’s Vision and Learning Lab (MITACS GRI), where I worked with Prof. Li Cheng on motion imitation learning and text-to-3D generation. I also had an enriching research internship at IIT Kharagpur, collaborating with Dr. Saumik Bhattacharya on multi-modal learning and action recognition in videos. Email / GitHub / Google Scholar / Resume / LinkedIn / |

|
Research'*' indicates equal contribution. |
|
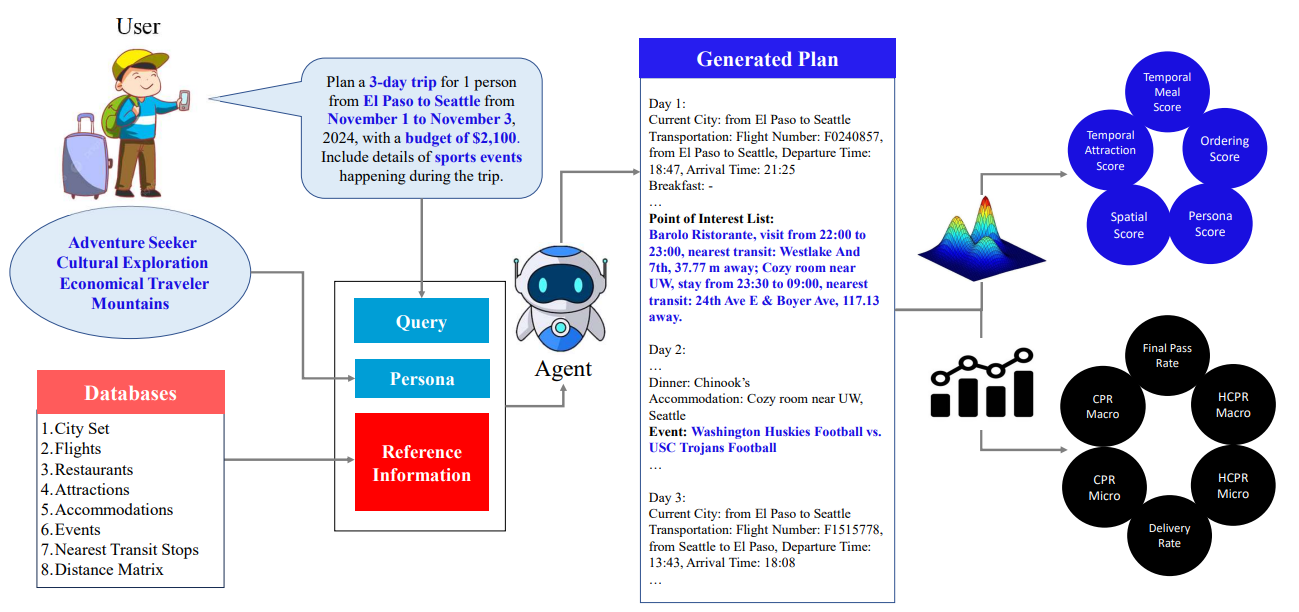
TripCraft: A Benchmark for Spatio-Temporally Fine Grained Travel PlanningSoumyabrata Chaudhuri, Pranav Purkar, Ritwik Raghav, Shubhojit Mallick, Manish Gupta, Abhik Jana, Shreya Ghosh ACL (Main), 2025 paper / code / We introduce TripCraft, a spatiotemporally coherent travel planning dataset that integrates real world constraints, including public transit schedules, event availability, diverse attraction categories, and user personas for enhanced personalization. |
|
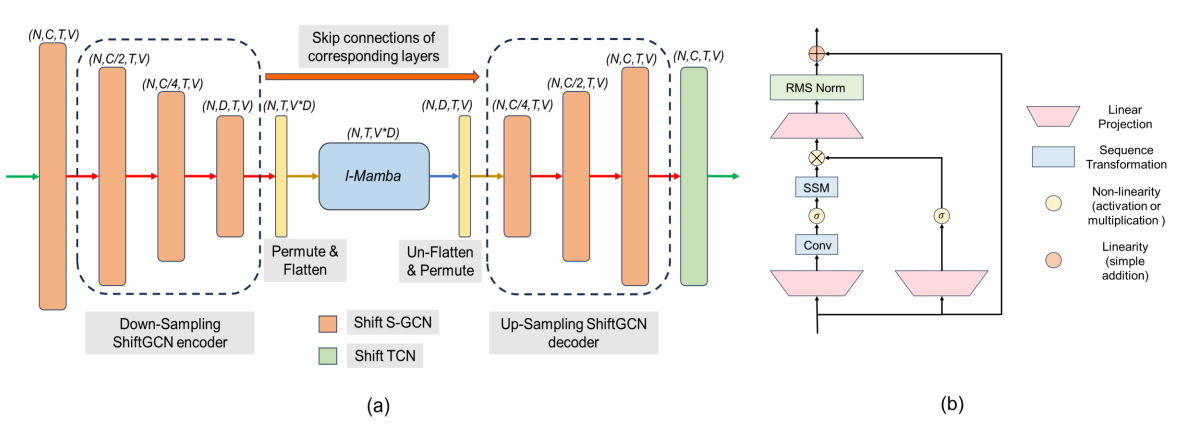
Simba: Mamba augmented U-ShiftGCN for Skeletal Action Recognition in VideosSoumyabrata Chaudhuri, Saumik Bhattacharya arxiv, 2024 paper / code / Simba is the inaugural attempt at leveraging the Mamba model for skeleton action recognition task in videos. |
|
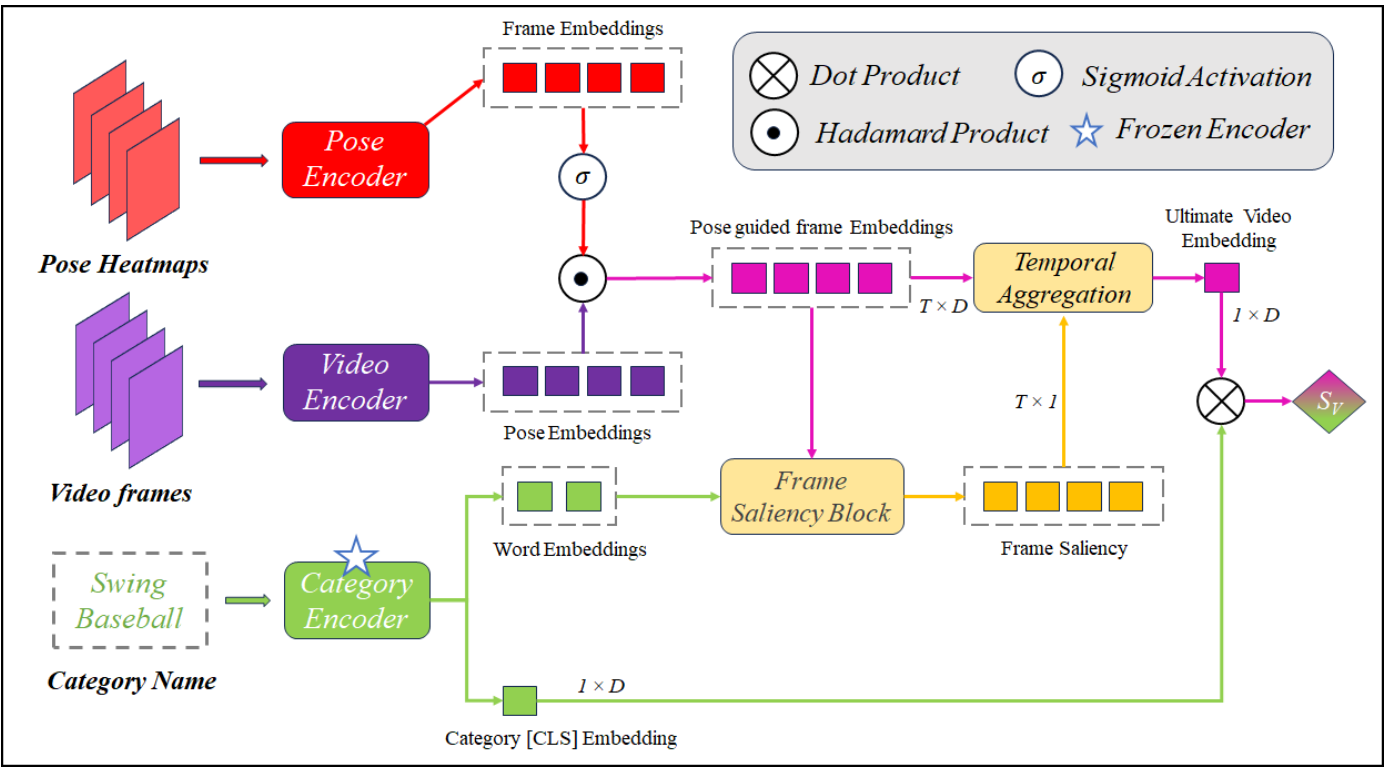
ViLP: Knowledge Exploration using Vision, Language and Pose Embeddings for Video Action RecognitionSoumyabrata Chaudhuri, Saumik Bhattacharya ACM ICVGIP (Oral), 2023 paper / code / ViLP explores cross-modal knowledge from the pre-trained vision-language model (e.g., CLIP) to introduce the novel combination of pose, visual information, and text attributes. |
|
Design and source code from Leonid Keselman's website |